EquiBot: SIM(3)-Equivariant Diffusion Policy for Generalizable and Data Efficient Learning
Jingyun Yang1* Zi-ang Cao1* Congyue Deng1 Rika Antonova1 Shuran Song1 Jeannette Bohg1
*Equal Contribution 1Stanford University
CoRL 2024
Abstract
Building effective imitation learning methods that enable robots to learn from limited data and still generalize across diverse real-world environments is a long-standing problem in robot learning. We propose EquiBot, a robust, data-efficient, and generalizable approach for robot manipulation task learning. Our approach combines SIM(3)-equivariant neural network architectures with diffusion models. This ensures that our learned policies are invariant to changes in scale, rotation, and translation, enhancing their applicability to unseen environments while retaining the benefits of diffusion-based policy learning such as multi-modality and robustness. We show on a suite of 6 simulation tasks that our proposed method reduces the data requirements and improves generalization to novel scenarios. In the real world, with 10 variations of 6 mobile manipulation tasks, we show that our method can easily generalize to novel objects and scenes after learning from just 5 minutes of human demonstrations in each task.ations in each task.
Video
Method Overview
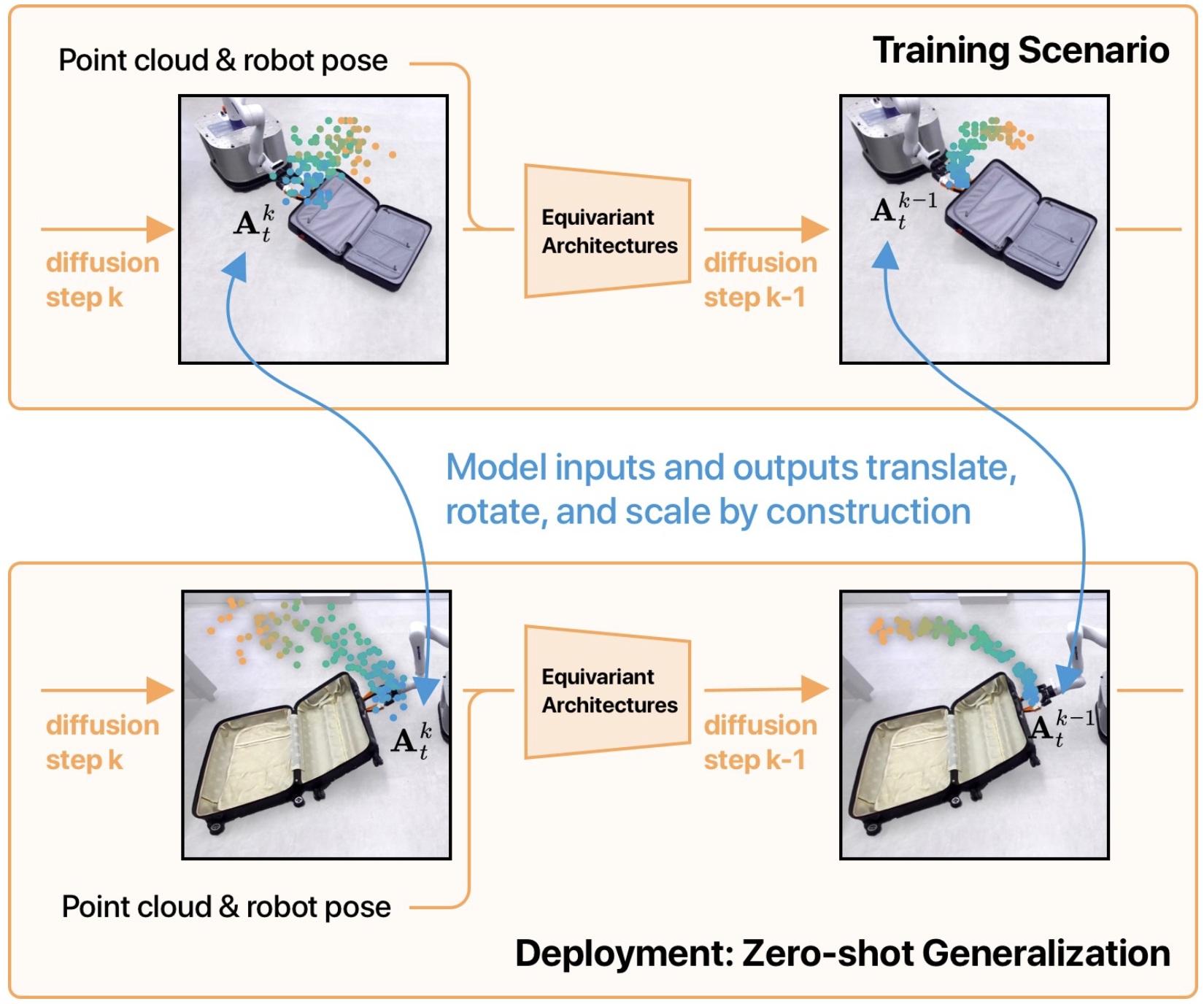
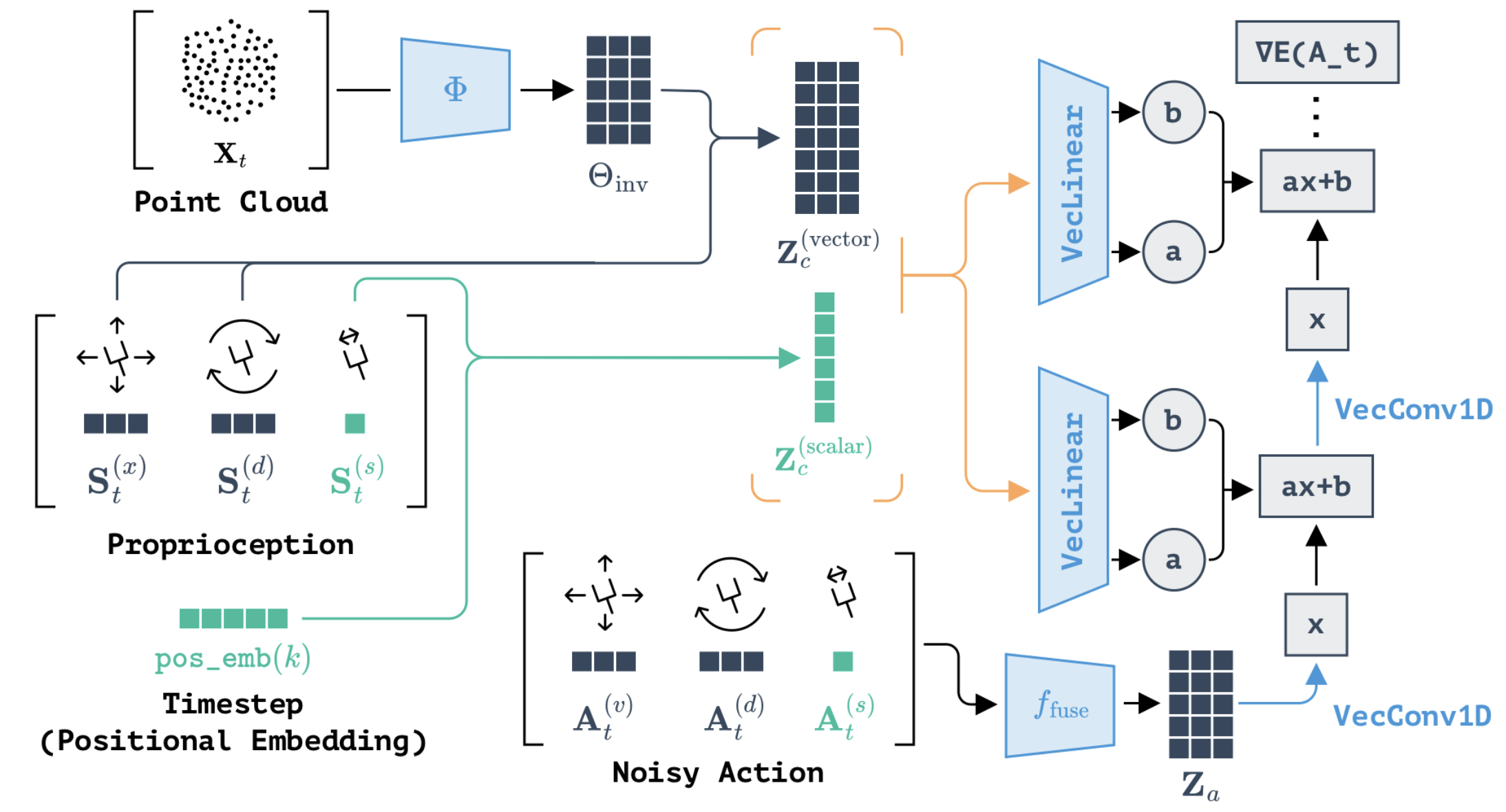
Given an input scene point cloud and robot proprioception, our method performs a series of diffusion steps to produce denoised actions with SIM(3)-equivariance (shown in the left figure). This means that when the inputs translate, rotate, and scale, the outputs are guaranteed to translate, rotate, and scale accordingly. Instead of relying on emergent properties from training, this equivariance is explicitly ensured by our model architecture (shown in the right figure). We demonstrate that this equivariance property enables our method to achieve zero-shot generalization to novel scenarios and objects in both simulation and real-world robot experiments.
Real Robot Setup
Tasks
In our real robot experiments, we show a series of experiments where we train mobile robots to perform everyday manipulation tasks from 5 minutes of single-view human demonstration videos. We select a suite of 6 tasks that involve diverse everyday objects, including rigid, articulated, and deformable objects (see Figure 6): (1) Push Chair: A robot pushes a chair towards a desk; (2) Luggage Packing: A robot picks up a pack of clothes and places it inside an open suitcase; (3) Luggage Closing: A robot closes an open suitcase on the floor; (4) Laundry Door Closing: A robot pushes the door of a laundry machine to close it; (5) Bimanual Folding: Two robots collaboratively fold a piece of cloth on a couch; (6) Bimanual Make Bed: Two robots unfold a comforter to make it cover the bed completely.
Data Collection
We collect 15 human demonstration videos for each real robot task. We use a ZED 2 stereo camera to record the movement of a human operator using their fingers to manipulate the objects of interest at 15 Hz. After data collection, we use an off-the-shelf hand detection model, an object segmentation model, and a stereo-to-depth model to parse out the human hand poses and object point clouds in each frame of the collected demos. We then subsample this data to 3 Hz and convert it into a format supported by our policy training algorithm. Below, we show sample human demonstrations for each task. In each task, we only collect human demos on a single object.
Real Robot Results
We train all methods for 1,000 epochs. After training, we evaluate each method for 10 episodes and record the success rate of the method. We vary the evaluation scenarios from the training scenarios differently in each task. In Laundry Door Closing, we perform evaluations in-distribution. In Push Chair, Luggage Closing, and Bimanual Make Bed, we evaluate with novel objects to make the evaluation out-of-distribution to the training data. In Luggage Packing and Bimanual Folding, we not only switch to novel objects but also translate and rotate the layout of the scene. Below, we show quantitative results for these experiments.
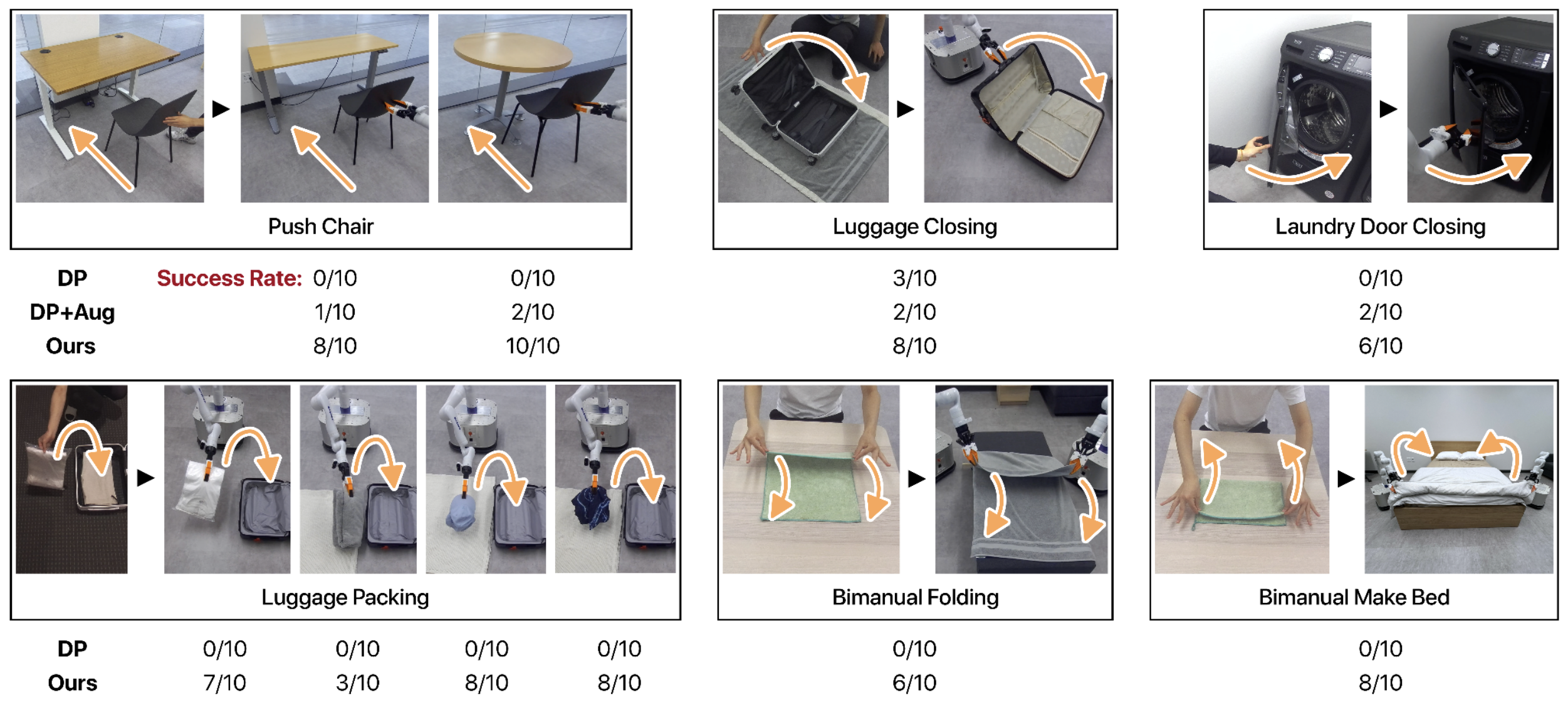
Push Chair to Longer Desk
DP
DP+Aug
Ours (EquiBot)
Push Chair to Circular Desk
DP
DP+Aug
Ours (EquiBot)
Close Luggage
DP
DP+Aug
Ours (EquiBot)
Laundry Door Closing
DP
DP+Aug
Ours (EquiBot)
Packing T-shirts
DP
Ours (EquiBot)
Packing Towel
DP
Ours (EquiBot)
Packing Cap
DP
Ours (EquiBot)
Packing Shorts
DP
Ours (EquiBot)
Bimanual Fold
DP
Ours (EquiBot)
Bimanual Make Bed
DP
Ours (EquiBot)
BibTeX
@inproceedings{yang2024equibot,
title={EquiBot: SIM(3)-Equivariant Diffusion Policy for Generalizable and Data Efficient Learning},
author={Yang, Jingyun and Cao, Zi-ang and Deng, Congyue and Antonova, Rika and Song, Shuran and Bohg, Jeannette},
booktitle={8th Annual Conference on Robot Learning},
year={2024},
}